The advanced concept of properties
-
@kt_ said in The advanced concept of properties:
This is easier:
Only initially. It tends to lead to vast piles of functions that don't really do anything, making it very difficult to track down where a bug actually is. (I've seen that sort of thing quite a few times.) The goal isn't keeping individual functions short; the goal is keeping the overall program clear.
-
@dkf said in The advanced concept of properties:
Some application areas are more verbose, requiring more code simply because there's more that has to be specified (even if it is simple to do so).
I have one such monsterous section in my code. It's basically a huge
if-else ifconstruct that does various things based on a certain field in a map it needs to process. The only two options (other than making an even more convoluted mess by separating the thing in multiple classes) are:- Current thing where it's a huge
if-else ifstatement with a bunch of data shuffling in each branch; or - Same thing, but body of each branch is separated into a function
There are maybe two branches that are similar enough to put into the same function, and even that is doubtful. So even if I move everything into functions you'll still have to search for
processEventXor whatever I'd call them, instead of searching forevent == "X".It's one of those tasks that simply don't lend themselves to producing very tidy code, at least in line count terms.
- Current thing where it's a huge
-
@kt_ said in The advanced concept of properties:
What I actually mean is:
var url = "http://google.com"; var contents = new WebClient().DownloadString(url); var regexQuery = "^[0-9]$"; var regex = new Regex(regexQuery); var matches = regex.Matches(contents );Over:
String url; string regexQuery; Regex regex; String contents; Matches matches; regexQuery = ^[0-9]$"; regex = new Regex(regexQuery); url = "http://google.com"; contents = new WebClient().DownloadString(url); matches = regex.Matches(contents);This is a simple example, but imagine there were many variables in a larger method
I might argue that in this case, the issue is partially the naming of your variables. If, instead of
matchesyou had something likenumberOfFoo, then I might prefer some variation of the second snippet, because it makes it clear from the start of the snippet that I am going to get a number of foos. When reading the first snippet, I might start wondering why do I need to query that URL, and then make did I pass the right options toDownloadString()(maybe I should be setting cookies first or whatever), and it's only when reaching the last line that I know that we weren't logging in to the service or doing complex stuff but just getting the number of foos from that page.Of course, you might say that on a 5 lines snippet, if I can't read back and forth then really I'm never going to understand much code, and this is true, but still, if small things can decrease the cognitive load needed, for me that's always good. We can split hairs for a long time on that, but again, my point is just to say that the "declare as late as possible" rule sometimes can be broken and increase the readability of the code.
And this is where I also disagrees, and the source for my other tongue-in-cheek comment about preferring one 500 lines function rather than 500 one line functions.
Well, I can't really agree with you here. I really like those small few lines long functions. First of all, they have names. Function names are better than comments. Comments age really bad, function names are definitely better maintained.
That's a good point. However you still have to hope that the maintainer who needs to change what the small function does will change the name as well. If we're talking long-term robustness of the code, this is not necessarily a given.
Second of all, you shouldn't really care about the HOW, when looking at what the public function does. You might want to at a later date, but at the first look what's important is WHAT.
True again, except that it only really works within the mind of the person who wrote it. The "edge cases" bit is really a strong issue here for me, as I said before.
CreateRange()is a good example here. Assuming we're talking about a list of real numbers (let's sayfloatordouble), what should happen if the list is empty? What should happen if you're in a language that has a nullable type and one (all?) item is null? What should happen if one (all?) item is NaN? +inf/-inf?So what is this function doing? Is it "create a range such that for any element e of the list, min <= e <= max"? Or "create a range that can be used e.g. on a graph to plot this list"? Typically with +/-inf, the first interpretation would mean that the range could go to +/-inf, with the second interpretation maybe you want to actually ignore those values. And with NaN (or null), the first interpretation probably doesn't mean anything. And with an empty list, the first interpretation allows returning (42, 42) as min/max whereas it wouldn't make sense for the second interpretation.
My point here is that what you call the "how", including the edge cases, are actually an integral part of what the function does. Unless the function is really absolutely and entirely trivial, but then the function cannot be more than one line and writing the function itself is just adding verbosity.
Speaking of that, I do really have an issue with the verbosity of the thing. One tiny function is, typically, at least 3 lines (
int foo() {,return 42;and}-- of course it does depend on the language (C/C++/... would actually require one more line for the declaration, or putting the function in the declaration which might be seen as making it too verbose), and the coding conventions for braces and stuff, but that's the idea), plus probably some whitespace around it. If we're talking about functions that are just one line long (or maybe 2), that adds up to a significant amount. Of course, I don't care about the length of a file in itself, but a longer file doesn't really seem that much better to me (and I'll come back to that in a minute).Another thing about the edge cases is the impact on the maintainability and the reuse: if you have these tiny functions, I hope that you are reusing them in several places rather than redoing the same function several times? But then, what if in one place you needed the first meaning of
CreateRange()and in another place the other meaning? And then you stumble onto a bug with one of these edge cases. You fix it in the place you found it, but did you think about searching for all other places whereCreateRange()is used and making sure your fix is what was expected in those places? By making a tiny function, you've now actually added a significant maintenance burden.Also, if you follow the rule that code should read like a newspaper: starting with the most important (top-level) things and then going deeper and deeper as you go down, it reads really well. Usually this means that the functions you call are right there, visible on your screen already.
I've heard that before, yes, but the thing is, it only works if you can keep reading with a fuzzy understanding of what happened before. In a newspaper, you can read something like "Mr Smith, leader of Bumfuckistan" without needing to know right now whether he is a president, prime minister, king, dictator, whether he was elected or inherited or took power by force. And only later in the article, when that becomes relevant to the story that is being told, the journalist (should) give you that information.
In code, some of that information might be needed right away to understand the rest, because code is not informal human communication, but a very precise language where everything holds together. While a dictator might be allowed to call the
goToWar()function directly, an elected one might first need to callgetAuthorizationFromParliement()(yeah, that analogy won't end well...).Also, this hierarchical view breaks when opening a file that is almost entirely made of tons of small functions. There is no way, by simply skimming the file, to get an idea of the flow between the functions, because each one is just a couple of calls to other bits. Larger functions are easier to quickly differentiate between "this is the main algorithm" and "these are just helper side-functions". Again, good names and comments and good code structure should help here, but my point is that going the many-tiny-functions route is not necessarily conductive to getting a more readable code.
@dkf said in The advanced concept of properties:
Only initially. It tends to lead to vast piles of functions that don't really do anything, making it very difficult to track down where a bug actually is. (I've seen that sort of thing quite a few times.)
Yes, that is one of the things that I'm trying to say...
The goal isn't keeping individual functions short; the goal is keeping the overall program clear.
Exactly! The overall point is not to have rules. Rules are stupid. Well, we already have rules that can't be broken, they are the syntax of the language. But when it comes to rules that are destined to humans (should I break this into functions or not?) what matter is that rules for humans can never be absolute (including this one, ha ha ha). And since we're talking humans, the goal is to be able to read/understand/fix/evolve the code easily, and for that, tiny functions are not necessarily a good thing.
-
@remi said in The advanced concept of properties:
Because it breaks my reading flow, and because it forces me to assume that the CreateRange() function does what I think it does, and because I can't check easily whether edge cases are handled like I think they are (such as, what is the range if params is empty? if it contains null values or NaN?
The point is that you should not be doing either of these. As soon as you look at the implementation you have disregarded encapsulation and abstraction. As soon as you look at the call, they you have avoided MYC [Minimal Yet Complete].
Yes, there are exceptions (we do not live in a perfect world)
-
@remi said in The advanced concept of properties:
You fix it in the place you found it, but did you think about searching for all other places where CreateRange() is used and making sure your fix is what was expected in those places?
The unit tests for each of those places will fail.

-
@thecpuwizard said in The advanced concept of properties:
The point is that you should not be doing either of these. As soon as you look at the implementation you have disregarded encapsulation and abstraction. As soon as you look at the call, they you have avoided MYC [Minimal Yet Complete].
I am not sure I understand what you mean... Anyway, encapsulation and abstraction is a good idea, when there is something to encapsulate and abstract. When it takes about as long to describe what the abstraction is doing vs. actually doing it (which is more or less what we are discussing with tiny functions), you are IMO making things worse, not improving them.
@thecpuwizard said in The advanced concept of properties:
@remi said in The advanced concept of properties:
You fix it in the place you found it, but did you think about searching for all other places where CreateRange() is used and making sure your fix is what was expected in those places?
The unit tests for each of those places will fail.
Sure (well, let me first laugh at the likelihood that you actually have tests that will actually catch that... now, let's assume that you do). Except you have still added some complexity to your flow of fixing the code, namely seeing that the test has failed and finding where it was, and finding how that change that you thought was totally unrelated actually wasn't, and finding how to fix both places at the same time (which in this case might mean actually duplicating the tiny function with two variants) and so on.
Which comes back to my main point, that tiny functions are in many cases more a hassle than a gain.
-
@pjh said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
@remi said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
@boomzilla said in The advanced concept of properties:
@remi There is a certain cleanliness of keeping all of your declarations in one place
But it doesn't make sense. The kinds of instructions that do list all of the prerequisites at the top are those instructions where you (i.e. The person) need to collect all of the materials. Recipes, woodworking instructions. But here you are the reader, not the preparer.
I disagree. You are the one preparing the understanding of the code (when you read it, obviously not when you write it...), and knowing the "ingredients" in advance can help understanding what some code is for.
I knew you'd go this way. But I don't think you are right here. The fact that gore declaring a bunch of ints and strings doesn't say a lot and even if they're named well, this doesn't really prepare me for what's gonna happen. The function's name should, but not seeing a bunch of variables there.
It's easier to understand what's happening when you see stuff being used, not when you see a bunch of stuff lying around.
Case in point from something I've had cause to mess around with recently:
static int snmp_considerVLAN(accesspoint_t* ap, const configInfo_t *ci){ const int *classarray = 0; int lastitem = 0; int currentVLAN, intendedVLAN; size_t f; int found; struct variable_list* v=0; char sa_tmp[INET_ADDRSTRLEN]; struct snmp_device_template* d = &ap->snmp_device; ...Changing With the Times

Melody got tapped to do a code review on a pull-request from a veteran team-member. It was… an interesting PR, in that very, very little changed. The code was terrible before anyone touched it- for example, the C-file started with 355 lines of variable declarations inside of the main method. It...
for example, the C-file started with 355 lines of variable declarations inside of the main method
-
@remi said in The advanced concept of properties:
Except you have still added some complexity to your flow of fixing the code, namely seeing that the test has failed and finding where it was, and finding how that change that you thought was totally unrelated actually wasn't, and finding how to fix both places at the same time (which in this case might mean actually duplicating the tiny function with two variants) and so on.
Which is much preferred to the opposite. Years ago I was doing work with a company, they had multiple implementations of things that should have been identical [27 of them in this case]. A bug was found, and fixed in 26 of the cases. The final case caused a failure in the field. The company was sued for negligence, and was nearly bankrupted (and it was not a small company).
""Every piece of knowledge must have a single, unambiguous, authoritative representation within a system".
-
@thecpuwizard Well, for the opposite to have actually worked, not only would you have needed to have the tiny function, you would also have needed for it to be called in the 27 places (and not only 26...). And to have tests that would have caught the error, but I'll be optimistic and assume that this would have been the case (although in a real world this is not given!).
The problem of the function being used in all 27 places is not just a snark from my part: if the function is tiny, and there are tens or hundreds of such tiny functions, what is the likelihood that all devs know that in some corner of your codebase, this tiny function already exists and reuse it? What is the likelihood that you will get twice very similar (or identical) tiny functions because of that? Yes, yes, code reviews should catch that. Will it catch absolutely all such cases?
And if everyone pushes strongly for reusing these tiny functions, what is the likelihood that you'll end up reusing the same tiny function in two totally unrelated places, to do two unrelated things that happen to be done in the same way, but are logically two different things, and that breaks when fixing one such case? (like with the example of
CreateRange()that we discussed above, there could be different contexts where you have very similar code but for different purposes and fixing a bug/edge-case might assume some knowledge of that context, which might be wrong elsewhere -- this is the classic case of trying too hard to factorize code that happens to look similar even if in fact it does different things)Again, I'm not against breaking the code into functions (well, duh!), but I really don't like the tiny-functions approach. For me, a function should be significant enough to do something non-trivial (*), otherwise putting that code in its own function may become a burden.
(*) getter/setters are probably an exception to that, but they are related to encapsulation, which is different. And of course, my rule is not so much a rule as a guideline, as I said above!
-
@remi - I 100% agree there are challenges (to say the least). The question for me, is which direction to strive for - with the understanding that there are limitations and hurdles.
A few things that help...
-
New semantic analysis tools that go far beyond lexical comparisons. Have three places in your code where you iterate an entire collection: one implemented as (for I=-0;i<count..) another as foreach and another as linq, but the bodies contain logically equivalent flow - FOUND automatically.
-
Rigorous attention to SOLID and DRY. If one is thinking about writing code, first demonstrate that it is being written in the (one) proper place. Maintaining (and using) a concordance of the codebase is a powerful (any usually overlooked tool)
-
-
@thecpuwizard Also, one aspect that should not be overlooked in these discussions is that not everyone works the same way, and that something that works for some people might not work for some other.
This is again one of those things where coding is not done for computers (things that (should) all behave in exactly the same way) but for humans, who are very variable. While there are common principles (no one is able to memorize a thousand different variables at the same time so you must break code into smaller chunks), there are also bits that may fit one dev but not the next one -- or even that might fit better into one culture or another!
-
@remi said in The advanced concept of properties:
@thecpuwizard Also, one aspect that should not be overlooked in these discussions is that not everyone works the same way, and that something that works for some people might not work for some other.
This is again one of those things where coding is not done for computers (things that (should) all behave in exactly the same way) but for humans, who are very variable. While there are common principles (no one is able to memorize a thousand different variables at the same time so you must break code into smaller chunks), there are also bits that may fit one dev but not the next one -- or even that might fit better into one culture or another!
100% agreement!!!!
At the same time I have never met anyone (and I most definitely include myself) who has achieved optimal, even for their own environment. There has always (in my experience) been room for improvement. Things become interesting (to me) in dealing with dozens of teams/organizations per year over a period of decades. Change triggers fear and will include discomfort. I have seen far more teams who remain frozen in one approach than willing to give alternatives an honest appraisal [this is not directed at you, but a wide audience].
-
@thecpuwizard said in The advanced concept of properties:
I have seen far more teams who remain frozen in one approach than willing to give alternatives an honest appraisal [this is not directed at you, but a wide audience].
Well, it could be in some part applied to myself, I'll admit that I'm not always as open as I could be towards alternatives. Though you also have to remember that we never work purely in an environnement where we can fiddle with the code like we want. The burden of maintaining what exists, and fulfilling various business needs, and dealing with the social aspects of the work (making our bosses happy, dealing with human flaws in our cow-orkers...) sometimes prevents us from doing much.
You've got to look at priorities, and improving the code itself is not always the best use that can be made of developers' time...
I'll speak out clearly here, for the sake of the discussion: we don't have a single automated test in our codebase (well, in the part that my team is directly handling), and that's something we would like to change. But we have a tangle of several 100' of thousands of LoC, maybe a few millions (that are relatively monolithic, it's not so much a lot of small modules), and above the technical challenge of actually adding tests (and learning how to do that usefully and efficiently), we have the huge challenge of actually proving, both to ourselves and to our managers, that the cost would be worth it. Some human factors play against us as well: unfortunately in that regard, we are all quite conservative in the way we do changes to existing code and therefore don't break that many things, so it makes it a bit harder to sell the idea of regression tests, for example, because we cannot point at many occurrences in the past where they would have helped...
I could list many reasons why adding tests would still be a good idea, and I would agree with all these reasons, but at the end of the day, when balanced with the other tasks at hand, and the social relationship between our team and the rest of the company, it is not obvious that this really is the best use of our ressources.
-
@thecpuwizard said in The advanced concept of properties:
@remi said in The advanced concept of properties:
You fix it in the place you found it, but did you think about searching for all other places where CreateRange() is used and making sure your fix is what was expected in those places?
The unit tests for each of those places will fail.
Oh, we got ourselves a comedian!

-
@marczellm said in The advanced concept of properties:
@remi said in The advanced concept of properties:
@pjh said in The advanced concept of properties:
Well as long as your functions aren't 500+ line behemoths,
I'd rather have one 500-lines function than 500 1-line functions...
void doStuff() { step1(); } void step1() { int i = 10; step2(i); } void step2(int& i) { for (int j=0; j<i; j++) step3(j); } // etc.?
void step3(int& j) { step4(--j); }
-
@dcon said in The advanced concept of properties:
@marczellm said in The advanced concept of properties:
@remi said in The advanced concept of properties:
@pjh said in The advanced concept of properties:
Well as long as your functions aren't 500+ line behemoths,
I'd rather have one 500-lines function than 500 1-line functions...
void doStuff() { step1(); } void step1() { int i = 10; step2(i); } void step2(int& i) { for (int j=0; j<i; j++) step3(j); } // etc.?
void step3(int& j) { step4(--j); }No no no, it's:
void step3(???) { ??? } int step4() { // Profit! }
-
@remi said in The advanced concept of properties:
No no no, it's:
But since an intern wrote it (and can't figure out why it never stops), your steps 3/4 need to be 4 and 5!
-
@remi said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
What I actually mean is:
var url = "http://google.com"; var contents = new WebClient().DownloadString(url); var regexQuery = "^[0-9]$"; var regex = new Regex(regexQuery); var matches = regex.Matches(contents );Over:
String url; string regexQuery; Regex regex; String contents; Matches matches; regexQuery = ^[0-9]$"; regex = new Regex(regexQuery); url = "http://google.com"; contents = new WebClient().DownloadString(url); matches = regex.Matches(contents);This is a simple example, but imagine there were many variables in a larger method
I might argue that in this case, the issue is partially the naming of your variables. If, instead of
matchesyou had something likenumberOfFoo, then I might prefer some variation of the second snippet, because it makes it clear from the start of the snippet that I am going to get a number of foos. When reading the first snippet, I might start wondering why do I need to query that URL, and then make did I pass the right options toDownloadString()(maybe I should be setting cookies first or whatever), and it's only when reaching the last line that I know that we weren't logging in to the service or doing complex stuff but just getting the number of foos from that page.Of course, you might say that on a 5 lines snippet, if I can't read back and forth then really I'm never going to understand much code, and this is true, but still, if small things can decrease the cognitive load needed, for me that's always good. We can split hairs for a long time on that, but again, my point is just to say that the "declare as late as possible" rule sometimes can be broken and increase the readability of the code.
I think this paragraph illustrates the best why we can't agree:
1
I think the second style is awful. It increases the number of lines and what adds is only noise. I see variables and I can prepare for what's gonna happen, but this doesn't really help much, because I don't how they're gonna be used. If I see "regex" -- what will this regex do? It's hard to name methods, it's even harder to name variables and it's even harder to name variables so that they make sense when you don't see what kind of content they will hold.
var websiteContents = new WebClient().DownloadString(url);tells more than:
string websiteContents; websiteContents = new WebClient().DownloadString(url);If these two are close, splitting out the declaration is useless. When they're far apart, the declaration itself tells me nothing.
2
It seems to me you keep thinking about functions in the C style: something you can always access form anywhere. In the example of
CreateRange(), you can't access this function from anywhere apart from this class. You're in a class that does X. It has a private method that's called CreateRange. It's obvious that it will create the range in the exact way that this class needs it.In this example, you don't care about arguments passed to
DownloadString()when reading this for the first time. You see you're downloading contents of a website and the original developers chose not to provide cookies, therefore cookies are not important.And this is where I also disagrees, and the source for my other tongue-in-cheek comment about preferring one 500 lines function rather than 500 one line functions.
Well, I can't really agree with you here. I really like those small few lines long functions. First of all, they have names. Function names are better than comments. Comments age really bad, function names are definitely better maintained.
That's a good point. However you still have to hope that the maintainer who needs to change what the small function does will change the name as well. If we're talking long-term robustness of the code, this is not necessarily a given.
Nothing is a given. In this case, we can at least hope it will happen. With a comment you can't even hope.
Second of all, you shouldn't really care about the HOW, when looking at what the public function does. You might want to at a later date, but at the first look what's important is WHAT.
True again, except that it only really works within the mind of the person who wrote it. The "edge cases" bit is really a strong issue here for me, as I said before.
CreateRange()is a good example here. Assuming we're talking about a list of real numbers (let's sayfloatordouble), what should happen if the list is empty? What should happen if you're in a language that has a nullable type and one (all?) item is null? What should happen if one (all?) item is NaN? +inf/-inf?So what is this function doing? Is it "create a range such that for any element e of the list, min <= e <= max"? Or "create a range that can be used e.g. on a graph to plot this list"? Typically with +/-inf, the first interpretation would mean that the range could go to +/-inf, with the second interpretation maybe you want to actually ignore those values. And with NaN (or null), the first interpretation probably doesn't mean anything. And with an empty list, the first interpretation allows returning (42, 42) as min/max whereas it wouldn't make sense for the second interpretation.
My point here is that what you call the "how", including the edge cases, are actually an integral part of what the function does. Unless the function is really absolutely and entirely trivial, but then the function cannot be more than one line and writing the function itself is just adding verbosity.
That's exactly what I talked about at the beginning of this post: you don't have to worry about that. CreateRange is a local function, it creates the exact type of range that you need. What it means exactly is implementation detail. It's something you should care about only when you really need to care about, i.e. when you're modifying the class.
Speaking of that, I do really have an issue with the verbosity of the thing. One tiny function is, typically, at least 3 lines (
int foo() {,return 42;and}-- of course it does depend on the language (C/C++/... would actually require one more line for the declaration, or putting the function in the declaration which might be seen as making it too verbose), and the coding conventions for braces and stuff, but that's the idea), plus probably some whitespace around it. If we're talking about functions that are just one line long (or maybe 2), that adds up to a significant amount. Of course, I don't care about the length of a file in itself, but a longer file doesn't really seem that much better to me (and I'll come back to that in a minute).It's a trade-off, but it's worth it. Of course, I'm not proposing 1-line functions here. They have their uses (like the @boomzilla's example where he shortened a condition this way), but they should be used only with great care.
Another thing about the edge cases is the impact on the maintainability and the reuse: if you have these tiny functions, I hope that you are reusing them in several places rather than redoing the same function several times? But then, what if in one place you needed the first meaning of
CreateRange()and in another place the other meaning? And then you stumble onto a bug with one of these edge cases. You fix it in the place you found it, but did you think about searching for all other places whereCreateRange()is used and making sure your fix is what was expected in those places? By making a tiny function, you've now actually added a significant maintenance burden.Again,
CreateRange()is a local function. It creates the kind of range you need. It's not general purpose. You don't want to reuse it. If you want to create other kind of range, you create yet another privateCreateRange()method in yet another class. If you need to create the same kind of range, abstract this away into a class.Also, if you follow the rule that code should read like a newspaper: starting with the most important (top-level) things and then going deeper and deeper as you go down, it reads really well. Usually this means that the functions you call are right there, visible on your screen already.
I've heard that before, yes, but the thing is, it only works if you can keep reading with a fuzzy understanding of what happened before. In a newspaper, you can read something like "Mr Smith, leader of Bumfuckistan" without needing to know right now whether he is a president, prime minister, king, dictator, whether he was elected or inherited or took power by force. And only later in the article, when that becomes relevant to the story that is being told, the journalist (should) give you that information.
In code, some of that information might be needed right away to understand the rest, because code is not informal human communication, but a very precise language where everything holds together. While a dictator might be allowed to call the
goToWar()function directly, an elected one might first need to callgetAuthorizationFromParliement()(yeah, that analogy won't end well...).You misunderstand this metaphor. "Reading like a newspaper" means you have the most important and high-level information at the top, nitty-gritty stuff further down, at the end.
Also, this hierarchical view breaks when opening a file that is almost entirely made of tons of small functions. There is no way, by simply skimming the file, to get an idea of the flow between the functions, because each one is just a couple of calls to other bits. Larger functions are easier to quickly differentiate between "this is the main algorithm" and "these are just helper side-functions". Again, good names and comments and good code structure should help here, but my point is that going the many-tiny-functions route is not necessarily conductive to getting a more readable code.
You should really take a look at the paste-in I posted. If your classes are 200 lines long tops, this shouldn't matter. And usually it's extremely easy to arrange those little functions in a way that makes it possible to see the all small functions the method you're reading calls on a single screen.
The problem of the function being used in all 27 places is not just a snark from my part: if the function is tiny, and there are tens or hundreds of such tiny functions, what is the likelihood that all devs know that in some corner of your codebase, this tiny function already exists and reuse it? What is the likelihood that you will get twice very similar (or identical) tiny functions because of that? Yes, yes, code reviews should catch that. Will it catch absolutely all such cases?
No, no, no. This small function is a local one. Functions are local. Classes provide functionality via public methods. Public methods call small private functions. You don't reuse small private functions.
Again, I'm not against breaking the code into functions (well, duh!), but I really don't like the tiny-functions approach. For me, a function should be significant enough to do something non-trivial (*), otherwise putting that code in its own function may become a burden.
What is the most trivial non-trivial something? How small functions do you oppose? Is 5 lines still to small?
-
@kt_ said in The advanced concept of properties:
var websiteContents = new WebClient().DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) websiteContents = client.DownloadString(url);
-
@thecpuwizard said in The advanced concept of properties:
The unit tests for each of those places will fail.
Not always. Picking a very dumb (but technically correct) sorting algorithm can cause major problems, yet not trip any (reliable) unit tests, as the problems show up principally in terms of performance. An example of this was in some code a colleague was looking at recently, which was using lists for many things and linear searching to detect if elements were present in those lists; changing the code to use hash tables accelerated it by several orders of magnitude. Was that a bug? The code was producing the right answers before, but that's often not the whole story.
Not all problems can be fixed in isolation, nor all fitness metrics evaluated on just the smallest pieces of code.
-
@raceprouk said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
var websiteContents = new WebClient().DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) websiteContents = client.DownloadString(url);Touche. :)
-
@raceprouk said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
var websiteContents = new WebClient().DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) websiteContents = client.DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) { websiteContents = client.DownloadString(url); }
-
@kt_ said in The advanced concept of properties:
var websiteContents = new WebClient().DownloadString(url);Next up: someone proposes abstracting the above so it no longer assumes that the contents are necessarily being retrieved over HTTP (or HTTPS). This requires converting the system to use factories and those don't actually assume that the method is called
DownloadString, as that makes a lot of assumptions that no longer are required to hold. The code has now become:var websiteContents = serviceContactFactoryBuilder.BuildServiceContactFactory(url).ContactServiceToRetrieveMessage();Or something like that. And it gets worse, as programmers who ought to know better discover that they can use lambdas to make the code even more generic and configurable and utterly impenetrable. All of which sounds like a joke, or maybe a thing that is being held up as a particularly ridiculous straw-man. If only. These sorts of monstrosities tend to crop up in code more and more often as the code becomes more enterprisey; XML might be a symptom, but these hyper-abstract towers of BS are the core of the menace. :(
-
@dkf said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
var websiteContents = new WebClient().DownloadString(url);Next up: someone proposes abstracting the above so it no longer assumes that the contents are necessarily being retrieved over HTTP (or HTTPS). This requires converting the system to use factories and those don't actually assume that the method is called
DownloadString, as that makes a lot of assumptions that no longer are required to hold. The code has now become:var websiteContents = serviceContactFactoryBuilder.BuildServiceContactFactory(url).ContactServiceToRetrieveMessage();I mean, I understand, people are stupid, but why would they do something like that here? Especially since it's just a simple example of tying variable declaration and assignment, not how to new-up things and download them from the web?
But if what you actually meant was to write a good rant, hey, I completely agree! :)
-
@kt_ said in The advanced concept of properties:
But if what you actually meant was to write a good rant, hey, I completely agree! :)
Never let a good rant go to waste!
-
@dkf said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
But if what you actually meant was to write a good rant, hey, I completely agree! :)
Never let a good rant go to waste!
QFT!
-
@kt_ said in The advanced concept of properties:
why would they do something like that here?
It's entirely possible the in the future the target contents might not come from the web, but a file archive, with a protocol not necessarily http, in a format not necessarily straight-up string-able (for instance, in a zip file). So you generalize it to abstract the path into a generated one that the factory can choose how it needs to access it, and then any time you want that content in theory the app would just auto adapt to the environment requirements instead of making assumptions.
At least, I think that's the idea. Never tried it myself I am not a factory.
-
@kt_ said in The advanced concept of properties:
I think the second style is awful. It increases the number of lines and what adds is only noise. I see variables and I can prepare for what's gonna happen, but this doesn't really help much, because I don't how they're gonna be used. If I see "regex" -- what will this regex do? It's hard to name methods, it's even harder to name variables and it's even harder to name variables so that they make sense when you don't see what kind of content they will hold.
Well, that was part of my point. Instead of naming the variable
regex, name it something useful and descriptive. Don't name an intn, name itnb_foosor whatever. This way you don't have to read the code that populate that variable, you already know what it will contain. You brought up the newspaper metaphor: the variable is the headline (well, OK, the function name is the headline... or is it the class that contains it? Seems like this metaphor is already breaking down ;-) ), when you read it you should know what it's about. The fact that it is a regexp is irrelevant (or redundant if it's in the type but that will depend on the language), what matters is what this regexp does. You were the first one to bring up the how vs. the what, I think...Again, I'm not arguing for old-style C-code with 100's of declarations at top. I'm saying that in some cases, putting a couple of declarations a bit early actually makes the code easier to follow. Because, exactly as you said, the important stuff is at the top.
If these two are close, splitting out the declaration is useless. When they're far apart, the declaration itself tells me nothing.
I disagree. It tells you that you are going to get a website contents, which is a very important information. Whether you get it from a WebClient() object or an HttpConnection() or an internal cache doesn't matter (at least not at first glance), so you first declare your
string websiteContentsand then populate it a few lines below, everything in between being related to how you will end up populating it. Let me repeat this in case it's not obvious: everything in between being related to how you will end up populating it. You are not putting the declaration miles away and mixed with irrelevant stuff, that would be stupid. But for me, it makes sense to start this block by telling what we will be doing. You might put a comment, but as you pointed out it's very brittle. You might do a function, yes, but in a sense that's another possible choice (that I dislike, but partly for other reasons). Or you might put the declaration of the "final" variable right before. That plays exactly the same role as putting code in a function, i.e. indicating what it will be about.It seems to me you keep thinking about functions in the C style: something you can always access form anywhere. In the example of
CreateRange(), you can't access this function from anywhere apart from this class. You're in a class that does X. It has a private method that's called CreateRange. It's obvious that it will create the range in the exact way that this class needs it.Well, what you propose then is even worse (to me) as you are going to create tons of identical functions in different classes (file, namespace, entity, whatever), each one being used at most once. I really don't see the point.
That's a good point. However you still have to hope that the maintainer who needs to change what the small function does will change the name as well. If we're talking long-term robustness of the code, this is not necessarily a given.
Nothing is a given. In this case, we can at least hope it will happen. With a comment you can't even hope.
If your tiny function is a private function used exactly once, I don't see why there would be more hope that the name will change than with using a comment. I would even argue for the opposite as the function name appears in 2 places (implementation/call) and even 3 if there is a declaration (depending on the language) (unless you go for lambda but then this goes against all your other arguments of using a function, so that would be even more useless). Which means that it needs to be changed in all those places, whereas a comment only exists in a single place. Yes, yes, you should have a refactoring tool in your IDE that does for you, but as much as we might wish it was the case, not everyone knows or uses them. Anyway, before you get carried away: my point is not that a comment is better, my point is that a comment is not necessarily worse, in that specific regard.
(also and because I thought of that about IDEs: if you only want to isolate some code to make it less visible, your IDE should be able to fold code, so you only need to put it into blocks or regions or whatever. That allows you all the benefits that you see in a function, i.e. hiding it from the rest, while removing most of the drawbacks that I see, i.e. verbosity and putting far away stuff that might actually be important...)
Again,
CreateRange()is a local function. It creates the kind of range you need. It's not general purpose. You don't want to reuse it. If you want to create other kind of range, you create yet another privateCreateRange()method in yet another class. If you need to create the same kind of range, abstract this away into a class.So when you read the code, you see
CreateRange()in many different places and they all look almost the same but actually they're not. I don't see how you can claim this makes the code more readable. It may ("may") have improved the readability of a single class, but at the cost of muddling the overall codebase. It's unlikely that devs will spend all their time looking at a single class, and seeing similar-but-different things everywhere will not help them.Also, this hierarchical view breaks when opening a file that is almost entirely made of tons of small functions. There is no way, by simply skimming the file, to get an idea of the flow between the functions, because each one is just a couple of calls to other bits.
You should really take a look at the paste-in I posted.
I did. And I got exactly the impression I describe above. I need to skip from one function to the next to see what that means. Ironically, what makes your code readable is that it uses what I'm advising for many declarations!
ProcessNextStuff()doesn't tell me much. Does that handle cancellation? I guess, but only because there is an aptly-named variable_processCancellationTokendeclared above (well, initialised since it's a class variable, but that's the same here). If that variable wasn't here, I could read that snippet and totally forget about the possibility that a cancellation could happen. Then, doesProcessNextStuff()handle the end of stream (file, queue, whatever)? Since it's in a loop on_finished, I assume it does, but this is not an information I get from the function name but from the variable above it. If I had the relevant code right here rather than deported in further functions, I could see right away that yes, that loop does change the_finishedflag at a number of places.And then let's come back to the top of your file: since you advocate declaring variables at the latest point, why did you declare all your class variables up there? (unless this is a constraint of the language? it wouldn't be the case in C++ at least) You are also breaking your own rule of putting most important stuff first. Unless you think that forewarning the reader about all the stuff that exists in the class at once is important, which was my point about declarations...
So it seems to me that, on the declaration bit, we are actually in agreement. On the functions thing, your example only reinforces my idea that this can be bad (not necessarily and not in all cases, of course, but it's not a 100% good thing).
The problem of the function being used in all 27 places is not just a snark from my part:
No, no, no. This small function is a local one.
I was answering to @TheCPUWizard comment on having one instance out of 27 of a code snippet that wasn't fixed. Using private local functions would not help at all in this case, so this is irrelevant.
What is the most trivial non-trivial something? How small functions do you oppose? Is 5 lines still to small?
Do you expect me to give you an absolute definition? As I said, guideline, not rule. @boomzilla 's example was 1 line and that was helpful to him, so in that case 1 line was not too small. I don't like the idea that you should aim to break code in many small functions. For me, this doesn't necessarily improves the readability of the code. Sometimes it does, many times it doesn't. I would object to a code review where I'm being told without justification "you should break your code in small functions". Show me some place where I've made a 500-lines function and ask to me to break it, yes. Or duplicated code, or a function that doesn't do a logical single thing (as a guideline, if you need to put "and" in your function name, such as "doStuffAndThing()", you probably want to break it into two!). But you'll have to show me a good reason for breaking that function, not some kind of abstract generic idea that "small functions are good", because they're not always.
-
@remi said in The advanced concept of properties:
to see what that means
This has turned into a great discussion... I think one of the differences in view points centers on the element I quoted above. When one sees a function/method/etc. call is it necessary to "go see"???
Do you do it for every method/function in your languages runtime? OR are you expected to know it?
Do you look at the machine code inside? OR do you trust encapsulations?
Do you figure out which transistors turn on and off, in what order? [Thank goodness I have not had to do this in decades, but it was once common].Now, don't get me wrong...It is HARD to write software that inspires this level of trust. It will never be achieved 100%. But, if one makes the investment [in my experience] then the payoffs can be huge!
-
@thecpuwizard said in The advanced concept of properties:
When one sees a function/method/etc. call is it necessary to "go see"???
Yes, that is indeed probably one of our core disagreement. My experience is that when it comes to business logic and high-level code, what a function does is never so well-defined that it can be entirely and un-equivocally be put into its name. So you very often need to be able to look at how it does something, because you're not just reading the code out of curiosity, you are trying to change it (fix a bug, add a feature...).
bool list::is_empty()is clear, no one doubts what it should be doing (if it doesn't it's a bug, and that may happen, but when reading code that uses it I immediately know what it is supposed to be doing.CreateRange(), well, no, sorry, I don't know. I mean, I get the overall idea, but there is no way just looking at the name that I can guess exactly what it will do in all cases.
-
@thecpuwizard said in The advanced concept of properties:
When one sees a function/method/etc. call is it necessary to "go see"???
Throughout my app, I have a lot of queries to pull up data in certain ways. The differences are often subtle. I find myself looking into the methods to figure out if a previous query is really applicable to whatever I'm doing at the moment.
@thecpuwizard said in The advanced concept of properties:
Do you look at the machine code inside?
I've only ever done something like this by accident in a debugger, I think. Or maybe when I was trying to reverse engineer something.
-
@boomzilla said in The advanced concept of properties:
Throughout my app, I have a lot of queries to pull up data in certain ways.
That's exactly my point, once you get into business-logic, even a small function is not actually a simple function, because it relies on the whole complexity of the system (vs. a system library function which should only rely on well-defined and controlled underlying things, and therefore should be easier to trust).
-
So we have isolated our differences in perspective. I am not saying one is better than the other in the general case; but for me (my firm, most of my clients) the investment over years to get that "level of trust" has paid off. I do not ask (or expect) that anyone adopts - but please consider that in the right circumstances it can be very valuable.
Thanks!
-
@nedfodder said in The advanced concept of properties:
@raceprouk said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
var websiteContents = new WebClient().DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) websiteContents = client.DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) { websiteContents = client.DownloadString(url); }*twitch*
string websiteContents; using (var client = new WebClient()) { websiteContents = client.DownloadString(url); }
-
@ben_lubar Enjoy your uninitialised variable warnings! :P
-
@raceprouk said in The advanced concept of properties:
@ben_lubar Enjoy your uninitialised variable warnings! :P
Those aren't warnings, and they won't come up in this case.
-
This post is deleted!
-
@raceprouk said in The advanced concept of properties:
Enjoy your uninitialised variable warnings!
FWIW, it's not a loop, and so the variable cannot be uninitialised in code that ordinarily follows the
using, as that assignment can only fail to occur if an exception is thrown and that prevents the variable's uses from being reachable.
-
@ben_lubar said in The advanced concept of properties:
@nedfodder said in The advanced concept of properties:
@raceprouk said in The advanced concept of properties:
@kt_ said in The advanced concept of properties:
var websiteContents = new WebClient().DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) websiteContents = client.DownloadString(url);*twitch*
string websiteContents = null; using (var client = new WebClient()) { websiteContents = client.DownloadString(url); }*twitch*
string websiteContents; using (var client = new WebClient()) { websiteContents = client.DownloadString(url); }*twitch*
string websiteContents; using (var client = new WebClient()) { websiteContents = client.DownloadString(url); }
-
@dkf said in The advanced concept of properties:
@raceprouk said in The advanced concept of properties:
Enjoy your uninitialised variable warnings!
FWIW, it's not a loop, and so the variable cannot be uninitialised in code that ordinarily follows the
using, as that assignment can only fail to occur if an exception is thrown and that prevents the variable's uses from being reachable.In fact, the first is likely to give a warning such as "assigned value is never used".
-
@zecc said in The advanced concept of properties:
@boomzilla said in The advanced concept of properties:
if( value == true ){ return true; } else if( value == false ){ return false; } else{ return FILE_NOT_FOUND; }where FILE_NOT_FOUND is the result of
(!true && !false).So,
false?
-
@anotherusername said in The advanced concept of properties:
@zecc said in The advanced concept of properties:
@boomzilla said in The advanced concept of properties:
if( value == true ){ return true; } else if( value == false ){ return false; } else{ return FILE_NOT_FOUND; }where FILE_NOT_FOUND is the result of
(!true && !false).So,
false?Boolean value = methodWhichReturnsWrapperBooleanAndMayReturnNull(); if (value == true) { return true; } else if (value == false) { return false; } else { return FILE_NOT_FOUND; }
-
-
-
@anotherusername said in The advanced concept of properties:
So,
false?Not sure if whoosh or playing straight face.
-
@zecc said in The advanced concept of properties:
@anotherusername said in The advanced concept of properties:
So,
false?Not sure if whoosh or playing straight face.
Short-circuiting.
It works, bitches.
I know what the joke was, but they way it was written it will, indeed, be
falseunambiguously. Using theif-else if-elseconstruct makes the joke work properly.
-
@onyx said in The advanced concept of properties:
Short-circuiting.
It works, bitches.Well then...
Boolean logic.
It too works, regardless of short-circuiting. Bitches.
-
@zecc said in The advanced concept of properties:
@onyx said in The advanced concept of properties:
Short-circuiting.
It works, bitches.Well then...
Boolean logic.
It too works, regardless of short-circuiting. Bitches.
It's not all in the joke, it's how you tell it.
-
@onyx said in The advanced concept of properties:
It's not all in the joke, it's how you tell it.
Thus endith the useful discussion....
-
@thecpuwizard said in The advanced concept of properties:
@onyx said in The advanced concept of properties:
It's not all in the joke, it's how you tell it.
Thus endith the useful discussion....
Getting too old already?

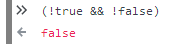
{kind=link}