How do I regexp?
-
Tip : Not like this.
/***********************************************************************
* Function: verifyPASSWORD
* Parameters: @strPassword-- String value from one of the Password fields.
* Returns : True if Password format is valid
* False if Password format is invalid
*
***********************************************************************/
function verifyPASSWORD(strPassword){
if(strPassword=="")
return false;
if (strPassword.length<6 || strPassword.length>15 )
{
return false;
}
else
{
if(strPassword.length==6)
{
var re = /\w{6,}/;
}
else if(strPassword.length==7)
{
var re = /\w{7,}/;
}
else if(strPassword.length==8)
{
var re = /\w{8,}/;
}
else if(strPassword.length==9)
{
var re = /\w{9,}/;
}
else if(strPassword.length==10)
{
var re = /\w{10,}/;
}
else if(strPassword.length==11)
{
var re = /\w{11,}/;
}
else if(strPassword.length==12)
{
var re = /\w{12,}/;
}
else if(strPassword.length==13)
{
var re = /\w{13,}/;
}
else if(strPassword.length==14)
{
var re = /\w{14,}/;
}
else
{
var re = /\w{15,}/;
}
if (!re.test(strPassword))
{
return false;
}
return true;
}
}I guess they just gave up using those complex regexps for email validation.
/***********************************************************************
* Function: verifyEmail
* Parameters: @strEmail-- String value from email fields.
* Returns : True if email format is valid
* False if email format is invalid
***********************************************************************/
function verifyEmail(strEmail){
var strTkn1,strTkn2;
var nTokenCount = 0;
var i = 0;
var nIndex,nLastIndex;
nIndex = strEmail.indexOf("@");
nLastIndex = strEmail.lastIndexOf("@");
if (strEmail.indexOf(" ") != -1){
return false;//contains whitespace
}
//compare the first and last index whether they are in the same position
if(nIndex== nLastIndex){
//Tokenise by @ symbol
strTkn1 = strEmail.split('@');
//get a count of the first set of Tokens
nTokenCount = strTkn1.length;
if((strTkn1[0]=="")||(strTkn1[1]==""))
return false;
//looping through the first set of tokens
for(i=0;i<nTokenCount;i+=1){
//allow first set of email string to have dots
//but,second set of email string must contains at least one dot
//alert(strTkn1[i] +" : " + strTkn1[i].substr(strTkn1[i].length-1,strTkn1[i].length) + i);
if((i!=0)&&
(strTkn1[i].substring(strTkn1[i].length-1,strTkn1[i].length)!="."))//check if the email string
//doesn't end with "."
nIndex = strTkn1[i].indexOf("."); //Search for the position of "."
else
nIndex = -1; //ignore if the string is the first subset
if (nIndex != -1){//if found, count the token
//Tokenise the sub string again by "."
strTkn2 = strTkn1[i].split('.');
nTokenCount += strTkn2.length;
if (nTokenCount >= 4){// e.g. test@mytest.com: 4 <==>('mytest','com'= 2) + ('test','mytest.com'=2)
return true;
}
}
}
}else{
return false;
}//field has more than one '@'
return false;
}
-
A google search for "email regexp" comes up with this:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
I mean, I guess I can assume that's correct but good luck if it's not and you have to debug that shit.
(Not that the given algorithm actually replicates that regex, but still)
-
@vt_mruhlin said:
I mean, I guess I can assume that's correct but good luck if it's not and you have to debug that shit.
I once had to do a strict postal address regex, which ended up being 10 lines long. It took me nearly a full day of staring at those 10 lines to get everything just perfect. There's nothing like writing regular expressions to make you appreciate whitespace.
-
@vt_mruhlin said:
A google search for "email regexp" comes up with this:
[snip]
I mean, I guess I can assume that's correct but good luck if it's not and you have to debug that shit.
It's wrong. Any regex for validating emails is wrong, since regex cannot validate (all) valid email addresses (at least by itself.)
Validate an E-Mail Address with PHP, the Right Way
The Internet Engineering Task Force (IETF) document, RFC 3696, “Application Techniques for Checking and Transformation of Names” by John Klensin, gives several valid e-mail addresses that are rejected by many PHP validation routines. The addresses: Abc\@def@example.com, customer/department=shipping@example.com and !def!xyz%abc@example.com are all valid.
What is the best regular expression for validating email addresses?
The grammar (specified in RFC 5322) is too complicated for that. Use a real parser or, better, validate by trying (to send a message).
Of course, you can get close with some regex's, but if that's all you're relying on, you're going to end up refusing some valid ones and allowing some invalid hosts. One pet peeve of mine is refusing a + in the local part.
What I ended up doing on on site was parsing the host out of it, seeing if there was an MX record for it, and doing some sanity checking on the local part. Sure I might get some invalid addresses, but then again, it's not a life or death situation if an email address is wrong.
-
I'm like this regexp for email:
^[A-Z0-9._%+-]+@(?:[A-Z0-9-]+\.)+[A-Z]{2,4} $
sure, its not totally following RFC, but good luck finding a real email address that does not validate. (not that its impossible just too small chance to make me care about it)
-
@Shinhan said:
I'm like this regexp for email:
^[A-Z0-9._%+-]+@(?:[A-Z0-9-]+.)+[A-Z]{2,4} $
sure, its not totally following RFC, but good luck finding a real email address that does not validate. (not that its impossible just too small chance to make me care about it)
While it's good to hear that you resemble the above regex (how? please discuss), did you exclude the .museum and .travel TLDs on purpose, or did you just decide that four letters in a TLD should be enough for everyone? (see http://www.iana.org/domains/root/db/ )
-
You had me at "regexp" + "verifyPASSWORD".
-
Why are you all worrying about the email address when the first half of the code is decidedly more shameful?
I mean, seriously. The programmer knows about the comma in the counter pattern {8,} but somehow fails to realise that IT HAS A PURPOSE, and that the entre first half can be replaced with return /\w{6,15}/.test(password)?
-
The grammar (specified in RFC 5322) is too complicated for [regular expression pattern matching]
Of course, this is the real WTF.
-
@dhromed said:
Which bit? That the 'grammar is too complicated' or that 'regex cannot cope with it?'The grammar (specified in RFC 5322) is too complicated for [regular expression pattern matching]
Of course, this is the real WTF.
-
@dhromed said:
Why are you all worrying about the email address when the first half of the code is decidedly more shameful?
I mean, seriously. The programmer knows about the comma in the counter pattern {8,} but somehow fails to realise that IT HAS A PURPOSE, and that the entre first half can be replaced with return /\w{6,15}/.test(password)?
They're trying to filter special characters, WTFy as that may be, so return !/\W/.test(password) would probably be better.
-
Well, what do you expect? Regexes are hard! Fortunately I just found a piece of code in the application that I have the ho
rrnor of maintaining which I am now going to use as a model whenever I need to filter input using a regexp:// remove incorrect symbols
StringBuffer result = new StringBuffer();
String regex = "[a-zA-Z]";
Pattern pattern = Pattern.compile(regex);
for (int i = 0; i < text.length(); i++) {
String charString = text.substring(i, i + 1);
Matcher matcher = pattern.matcher(charString);
if (matcher.find()) {
result.append(charString);
}
}Truely, a master has been at work here. I am humbled...
-
At least that example allows addresses in the .name and .info domains, which I use and which sometimes get rejected by mail validation scripts written by idiots.
-
@PJH said:
@dhromed said:
Which bit? That the 'grammar is too complicated' or that 'regex cannot cope with it?'The grammar (specified in RFC 5322) is too complicated for [regular expression pattern matching]
Of course, this is the real WTF.
I do not hold the irrational faith that regex will one day bring about world peace, therefore I have produced an illustration, in order to put complexities in some kind of perspective:
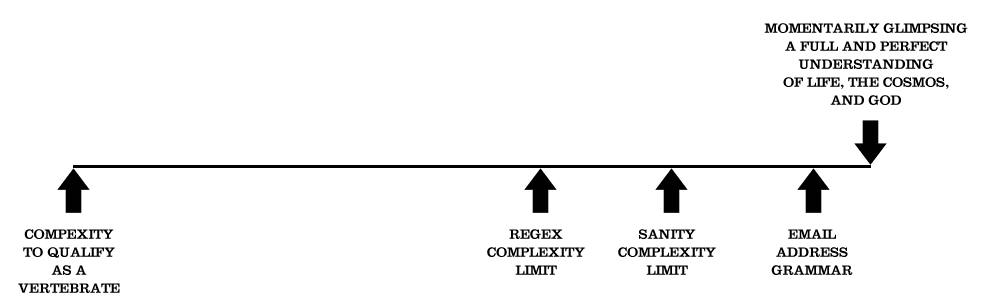
-
@mann_jess said:
There's nothing like writing regular expressions to make you appreciate whitespace.
This is where the /x modifier comes in handy (in languages that support it).
-
@asuffield said:
The whole concept is braindamaged anyway.
If you want to validate that
an email address is correct, send it a mail with a validation link in
it, and tell the user to go follow it.If you aren't going to
bother, then why waste time on partial tests that still don't tell you
whether it's the right email address? Either you care about having this
person's address (in which case you need to validate it properly), or
you don't (in which case you shouldn't be bothering).
QFT
-
@JvdL said:
Yeah, and why bother with JavaScript validation when you have to validate server-side anyway?@asuffield said:
The whole concept is braindamaged anyway.
If you want to validate that an email address is correct, send it a mail with a validation link in it, and tell the user to go follow it.
If you aren't going to bother, then why waste time on partial tests that still don't tell you whether it's the right email address? Either you care about having this person's address (in which case you need to validate it properly), or you don't (in which case you shouldn't be bothering).
QFT
EDIT: Ok, fine. This is probably not a case where we can benefit from early validation because we are already server-side. But maybe, just maybe, we can save some bandwidth by not trying to send messages to "obviously invalid" addresses.
-
@dhromed said:
@PJH said:
@dhromed said:
Which bit? That the 'grammar is too complicated' or that 'regex cannot cope with it?'The grammar (specified in RFC 5322) is too complicated for [regular expression pattern matching]
Of course, this is the real WTF.
I do not hold the irrational faith that regex will one day bring about world peace, therefore I have produced an illustration, in order to put complexities in some kind of perspective:
QFT.
Seriously, though, the mail RFCs are the most over-complicated pieces of shit imaginable. And SMTP is, by far, the worst.
-
@Zecc said:
Yeah, and why bother with JavaScript validation when you have to validate server-side anyway?
Sanity check before sending stuff over the wire.(i.e. JS specifically should not be 'validation.' Where 'validation' is stuff you do before accepting the data into your database/whereever.)e.g. if it doesn't have an @ sign and at least one dot after the @ sign, then it's probably not an email address; why bother allowing the form to be sent to the server if it's clearly not a valid email address?
Of course if the user has deliberately disabled JS client side, there's nothing you can do about it, but that's no reason to use it for the majority of users who do have it enabled.
-
@Zecc said:
Yeah, and why bother with JavaScript validation when you have to validate server-side anyway?
EDIT: Ok, fine. This is probably not a case where we can benefit from early validation because we are already server-side. But maybe, just maybe, we can save some bandwidth by not trying to send messages to "obviously invalid" addresses.
-
@PJH said:
e.g. if it doesn't have an @ sign and at least one dot after the @ sign, then it's probably not an email address; why bother allowing the form to be sent to the server if it's clearly not a valid email address?
Because the web-app will have server-side validation and error messages anyway. Why duplicate the effort? If you don't want to submit the form, at least use AJAX or something to send the field to the server and have it spit back a response. I would say that works just as well as client-side checking and doesn't duplicate effort.
-
@PJH said:
What is the best regular expression for validating email addresses?
The grammar (specified in RFC 5322) is too complicated for that. Use a real parser or, better, validate by trying (to send a message).
This is wrong. That grammar is just a regular language, which can be mapped directly to an NFA (i.e. by a regex). Perhaps it looked too complicated to the poster.
-
@Zecc said:
EDIT: Ok, fine. This is probably not a case where we can benefit from early validation because we are already server-side. But maybe, just maybe, we can save some bandwidth by not trying to send messages to "obviously invalid" addresses
Man, screw that. Let the SMTP server handle address validation. "Wasted bandwidth" for invalid addresses? Puh-leeze. A few k of text is nothing.
-
Mental note: next time put "Hmmm... irony" in the text rather than as a tag.
@JvdL said:
Here's why <-- corrected link, without the space that CS loves to add at the end
-
@Zecc said:
Mental note: next time put "Hmmm... irony" in the text rather than as a tag.
I presume that's supposed to go to a particular post in that thread, but it doesn't have the #whatever on the end. Maybe this?@JvdL said:
Here's why <-- corrected link, without the space that CS loves to add at the end
-
CS screwed me over twice. Apart from the broken link, my intended reply was: Here's why you should not bother to validate JS, because 999 out of a 1000 times the JS validation will be incomplete and you're bound to one day piss off a customer who was just about to make a million dollar purchase on your web site.
-
@JvdL said:
CS screwed me over twice. Apart from the broken link, my intended reply was: Here's why you should not bother to validate JS, because 999 out of a 1000 times the JS validation will be incomplete and you're bound to one day piss off a customer who was just about to make a million dollar purchase on your web site.
One site I'm working on now uses <samp>/@.+\./</samp> on the client-side, but has a more robust parser on the server-side.
This way, we can still filter out obviously bad email addresses* without having to make a request to the server, but allow uses maximum control over input.
* name@localhost isn't really an invalid email**, but there's no way anyone should be able to register with that one anyways.
** Although, given these RFC's complexity, it could be.
-
@JvdL said:
CS screwed me over twice. Apart from the broken link, my intended reply was: Here's why you should *not* bother to validate JS, because 999 out of a 1000 times the JS validation will be incomplete and you're bound to one day piss off a customer who was just about to make a million dollar purchase on your web site.
Totally. If you're going to do anything, just check for an @ and a .. That seems to be the only thing that can be reliably checked via JS.
-
@morbiuswilters said:
Man, screw that. Let the SMTP server handle address validation. "Wasted bandwidth" for invalid addresses? Puh-leeze. A few k of text is nothing.
Not that this is necessarily solved by a naive regex, but I think the major risk here is that if someone decides to DoS your site, they can DoS your mail server by proxy and/or potentially get you blacklisted. It's almost like the SMTP equivalent of XSS - they can't control the content of the e-mail messages, but it's still a bad situation to be in.
But that problem really needs to be solved separately anyway, usually with some off-the-shelf spambot detection product, or a limit on successive registration attempts.
-
@ounos said:
@PJH said:
This is wrong. That grammar is just a regular language, which can be mapped directly to an NFA (i.e. by a regex). Perhaps it looked too complicated to the poster.What is the best regular expression for validating email addresses?
The grammar (specified in RFC 5322) is too complicated for that. Use a real parser or, better, validate by trying (to send a message).
No, it's you who's wrong; the grammar needs at least a push-down automaton to implement (which can't be mapped to an NFA due to the lack of storage space in it), the culprit being the possibility of nested comments in an email address. (When publishing my email address online, I normally put nested comments in; no website I've ever seen that tries to validate emails can handle it, but then, no spambot seems to be able to either.) A regex can handle any given depth of comment nesting; but (without, say, Perl or PCRE extensions that allow recursion) you can't write a regex that allows for an unbounded number of nested comments.
-
@morbiuswilters said:
Man, screw that. Let the SMTP server handle address validation. "Wasted bandwidth" for invalid addresses? Puh-leeze. A few k of text is nothing.
You’ve clearly not been introduced to Yahoo!’s performance rules. If you were to say this to them, they would probably try to put your head on a pike. I have never, ever seen a group of people that so clearly have been deprived of carnal pleasure for too long. Given the footprint and complexity of YUI compared to some other JS frameworks, I almost feel like they went overboard on the performance rules to try to compensate for their horrifying toolkit.
-
@snover said:
@morbiuswilters said:
Man, screw that. Let the SMTP server handle address validation. "Wasted bandwidth" for invalid addresses? Puh-leeze. A few k of text is nothing.
You’ve clearly not been introduced to Yahoo!’s performance rules. If you were to say this to them, they would probably try to put your head on a pike. I have never, ever seen a group of people that so clearly have been deprived of carnal pleasure for too long. Given the footprint and complexity of YUI compared to some other JS frameworks, I almost feel like they went overboard on the performance rules to try to compensate for their horrifying toolkit.I'm aware of them. I know one of the lead devs of YUI. He was the second-worst programmer I've ever known. Like, he wouldn't write functions because "too many functions is slow" so he liked to copy-paste code all over the place. He had an uncanny knack for introducing bugs every 3 lines of code or so (and those 3 lines were probabaly copy-pasted in 40 places). He didn't understand OOP so all of his classes had only 4000-line constructors that handled all the logic and maintained state mostly by global vars. As part of his "functions are slow" rule, he liked to write functions that did 10 different things and had an "action" parameter passed that branched between one of a dozen if/else statements, each of which averaged 400 lines. He didn't understand normalization and liked to store fields in the DB as pipe-separated text columns or create tables with 100 columns named "field_1", "field_2", "field_3" and just add more columns when someone broke the software by needing more fields than we supported. And so on.
So, I don't really listen to anything Yahoo has to say.
-
After reading all of that, I’m afraid to know who counts as the worst programmer you ever knew. Based on my own personal experience recently, I’d nominate the entire team at DoubleClick.
-
@ais523 said:
No, it's you who's wrong; the grammar needs at least a push-down automaton to implement (which can't be mapped to an NFA due to the lack of storage space in it), the culprit being the possibility of nested comments in an email address. (When publishing my email address online, I normally put nested comments in; no website I've ever seen that tries to validate emails can handle it, but then, no spambot seems to be able to either.) A regex can handle any given depth of comment nesting; but (without, say, Perl or PCRE extensions that allow recursion) you can't write a regex that allows for an unbounded number of nested comments.
Almost all regex implementations allow recursion.
-
@XIU said:
Almost all regex implementations allow recursion.
his point still stands as he was responding to this:
@ounos said:
This is wrong. That grammar is just a regular language, which can be mapped directly to an NFA (i.e. by a regex). Perhaps it looked too complicated to the poster.