Internet Archive says they'll start ignoring robots.txt
-
Wasn't quite sure if this should go here or in the Sidebar, but...
Wonder if this is going to put any extra strain on anyone at some point, server-wise.
-
'We have also seen an upsurge of the use of robots.txt files to remove entire domains from search engines when they transition from a live web site into a parked domain, which has historically also removed the entire domain from view in the Wayback Machine. In other words, a site goes out of business and then the parked domain is “blocked” from search engines and no one can look at the history of that site in the Wayback Machine anymore.
Um, do the parked domains owners tap into the time stream and rewrite the robots.txt at every point in the past, present or future? Because I have no idea why hiding the site in 2016 would mean you can't read a snapshot from 2012.
-
@Maciejasjmj said in Internet Archive says they'll start ignoring robots.txt:
'We have also seen an upsurge of the use of robots.txt files to remove entire domains from search engines when they transition from a live web site into a parked domain, which has historically also removed the entire domain from view in the Wayback Machine. In other words, a site goes out of business and then the parked domain is “blocked” from search engines and no one can look at the history of that site in the Wayback Machine anymore.
Um, do the parked domains owners tap into the time stream and rewrite the robots.txt at every point in the past, present or future? Because I have no idea why hiding the site in 2016 would mean you can't read a snapshot from 2012.
The internet archive uses the current robots.txt to determine what they can show. I assume they'll still honor robots.txt when downloading pages.
-
Because in the history of nowhere did anyone go "oh, the internet archive is archiving me, I don't want that any more" and update robots.txt.
-
@ben_lubar said in Internet Archive says they'll start ignoring robots.txt:
. I assume they'll still honor robots.txt when downloading pages.
Article says:
for both crawling and displaying web pages
-
@Arantor said in Internet Archive says they'll start ignoring robots.txt:
Because in the history of nowhere did anyone go "oh, the internet archive is archiving me, I don't want that any more" and update robots.txt.
Mayhaps the concept of "You put it on the internet, it's there forever, deal with it sucker" will catch on.
Which is basically the mission statement of IA.
-
@Weng said in Internet Archive says they'll start ignoring robots.txt:
@Arantor said in Internet Archive says they'll start ignoring robots.txt:
Because in the history of nowhere did anyone go "oh, the internet archive is archiving me, I don't want that any more" and update robots.txt.
Mayhaps the concept of "You put it on the internet, it's forever, deal with it sucker" will catch on.
The EU disagrees (and i disagree with them.)
-
@accalia The EU also thinks it's important to make web pages spam users with notifications most of them don't understand (Cookies? Sounds tasty)
-
@Jaloopa said in Internet Archive says they'll start ignoring robots.txt:
@accalia The EU also thinks it's important to make web pages spam users with notifications most of them don't understand (Cookies? Sounds tasty)
I'm waiting to see what happens with GDPR.
-
@Jaloopa said in Internet Archive says they'll start ignoring robots.txt:
@accalia The EU also thinks it's important to make web pages spam users with notifications most of them don't understand (Cookies? Sounds tasty)
the EU has their panties in a twist. someone should untwist them.
or maybe i can get @Perverted_Vixen to steal them?
-
@accalia give 'em a wedgie.
-
@Arantor said in Internet Archive says they'll start ignoring robots.txt:
@accalia give 'em a wedgie.
can i steal their pants and undies after?
-
@Perverted_Vixen go for it.
-
@Perverted_Vixen said in Internet Archive says they'll start ignoring robots.txt:
can i steal their pants and undies after?
mod edit: A bit risque for a thread about crawling bots, don't you think?
LaoC edit: it's a tamed version of a clbuttic piece of art so ... well, maybe for the US :p
-
@Weng People should start firewalling them out. Crawlers that don't respect robots.txt are malware.
-
@Arantor said in Internet Archive says they'll start ignoring robots.txt:
Because in the history of nowhere did anyone go "oh, the internet archive is archiving me, I don't want that any more" and update robots.txt.
I did exactly that once.
The internet needs to be able to forget things. If archive.org is going to stop using robots.txt for that purpose, they need to introduce some other mechanism.
EDIT: more to the point, I owned the copyright to the stuff I'd posted on the web, and archive.org was reproducing it without explicit permission. They were already on the wrong side of both ethics and the law.
-
@blakeyrat me too.
But since the only recognised method has now been ignored, guess we blacklist their user agent.
-
Then someone decides a malicious way to entrap their crawler. Designs a site that spawns pages as its crawled. Spreads the idea around the internet....
-
@blakeyrat said in Internet Archive says they'll start ignoring robots.txt:
they need to introduce some other mechanism.
They already have one, IIRC. You can email them to request a site be removed from the archive, though I don't know whether they have conditions attached to that.
-
@blakeyrat Some stuff will have historical value after our copyrights are all expired and we're all dead.
IMO they should crawl following the current robots.txt, but only display what the authors authorized and things already in public domain.
We may never get a page snapshot in public domain because copyright keeps being extended, but that's another problem.
-
@wharrgarbl That might be a reasonable compromise.
-
@wharrgarbl said in Internet Archive says they'll start ignoring robots.txt:
IMO they should crawl following the current robots.txt, but only display what the authors authorized and things already in public domain.
IMHO they should archive every page regardless of what robots.txt says, but not necessarily display it (I’m not sure whether that should use robots.txt as it was when the page was archived or when it’s viewed, though — both have their pros and cons). This leaves it possible to make the information public later on, when copyright has expired or is lifted by whoever owns it.
-
@blakeyrat said in Internet Archive says they'll start ignoring robots.txt:
The internet needs to be able to forget things. If archive.org is going to stop using robots.txt for that purpose, they need to introduce some other mechanism.
EDIT: more to the point, I owned the copyright to the stuff I'd posted on the web, and archive.org was reproducing it without explicit permission. They were already on the wrong side of both ethics and the law.
They have some other mechanism.
Your site's robots.txt is not, was never, and will never be "to forget things". There is absolutely nothing in robots.txt that can say "and you must also delete anything that you've saved when you crawled previously, even when it was allowed". If your robots.txt allowed them to crawl previously, then your sole recourse is to request that your material be removed on copyright grounds, and they provide a pathway for you to request that. It's not robots.txt. It never was.
-
@Gurth said in Internet Archive says they'll start ignoring robots.txt:
IMHO they should archive every page regardless of what robots.txt says
The purpose of robots.txt is, at its most basic level, to prevent bots from overloading the server with traffic; as such, no well-behaved bot should crawl a website "regardless of what robots.txt says".
@Gurth said in Internet Archive says they'll start ignoring robots.txt:
I’m not sure whether that should use robots.txt as it was when the page was archived or when it’s viewed, though — both have their pros and cons
The only thing that robots.txt tells you is whether your bot is allowed to crawl the site right now. If crawling is allowed, it may tell also you that certain rate limitations are being imposed. Things that robots.txt does not tell you:
- whether the site's content is copyrighted
- which parts of the site's content are copyrighted
- whether you're allowed to mirror its content
- under what conditions you're allowed to mirror its content
- how long you're allowed to mirror its content
- whether you're allowed to continue mirroring content that it previously had allowed your bot to download
-
@anotherusername said in Internet Archive says they'll start ignoring robots.txt:
The purpose of robots.txt is, at its most basic level, to prevent bots from overloading the server with traffic; as such, no well-behaved bot should crawl a website "regardless of what robots.txt says”.
And that is rather at odds with the goal of preserving for posterity what’s on the site right now.
The only thing that robots.txt tells you is whether your bot is allowed to crawl the site right now.
Which makes it somewhat strange that the Internet Archive apparently uses the current version to decide what to display of older versions of the site.
-
@Gurth said in Internet Archive says they'll start ignoring robots.txt:
And that is rather at odds with the goal of preserving for posterity what’s on the site right now.
Then have someone download it manually. It says no bots; it doesn't say you can't download and preserve it.
-
@Gurth said in Internet Archive says they'll start ignoring robots.txt:
@anotherusername said in Internet Archive says they'll start ignoring robots.txt:
The only thing that robots.txt tells you is whether your bot is allowed to crawl the site right now.
Which makes it somewhat strange that the Internet Archive apparently uses the current version to decide what to display of older versions of the site.
Agreed.
-
@anotherusername A png generated by a proper browser of the same age would be more useful too. Lot's of stuff are broken there the way they do it.
-
@anotherusername said in Internet Archive says they'll start ignoring robots.txt:
@blakeyrat said in Internet Archive says they'll start ignoring robots.txt:
The internet needs to be able to forget things. If archive.org is going to stop using robots.txt for that purpose, they need to introduce some other mechanism.
EDIT: more to the point, I owned the copyright to the stuff I'd posted on the web, and archive.org was reproducing it without explicit permission. They were already on the wrong side of both ethics and the law.
They have some other mechanism.
Your site's robots.txt is not, was never, and will never be "to forget things". There is absolutely nothing in robots.txt that can say "and you must also delete anything that you've saved when you crawled previously, even when it was allowed". If your robots.txt allowed them to crawl previously, then your sole recourse is to request that your material be removed on copyright grounds, and they provide a pathway for you to request that. It's not robots.txt. It never was.
By default, everything composed by people will have copyright, and there's no need to register for that. Therefore, all webpages that we create have copyright.
Now, just file copyright claim on each and every content of your site, will they help you delete the archived image of your website?
-
@cheong said in Internet Archive says they'll start ignoring robots.txt:
By default, everything composed by people will have copyright, and there's no need to register for that. Therefore, all webpages that we create have copyright.
True.
@cheong said in Internet Archive says they'll start ignoring robots.txt:
Now, just file copyright claim on each and every content of your site, will they help you delete the archived image of your website?
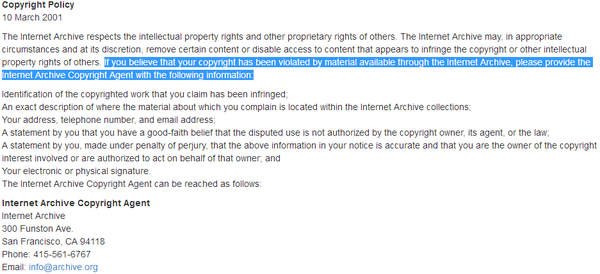
Yes. As it said, "The Internet Archive respects the intellectual property rights and other property rights of others." That means if you don't want them to archive copyrighted content that you have created, you can ask them to remove it, and they will.
-
@anotherusername said in Internet Archive says they'll start ignoring robots.txt:
Yes. As it said, "The Internet Archive respects the intellectual property rights and other property rights of others." That means if you don't want them to archive copyrighted content that you have created, you can ask them to remove it, and they will.
That's not OK, you can't pirate stuff and just delete after the copyright owner complains.
-
@wharrgarbl said in Internet Archive says they'll start ignoring robots.txt:
@anotherusername said in Internet Archive says they'll start ignoring robots.txt:
Yes. As it said, "The Internet Archive respects the intellectual property rights and other property rights of others." That means if you don't want them to archive copyrighted content that you have created, you can ask them to remove it, and they will.
That's not OK, you can't pirate stuff and just delete after the copyright owner complains.
Copyright law explicitly provides provisions for libraries and archives. Their operation is not in violation of copyright. They aren't "pirating".
For further reading:
-
@anotherusername said in Internet Archive says they'll start ignoring robots.txt:
Copyright law explicitly provides provisions for libraries and archives. Their operation is not in violation of copyright. They aren't "pirating".
Putting the words "archive" or "library" in your name isn't enough. From your own links:
In addition, however, "any such copy or phonorecord that is reproduced in digital format" may not be "made available to the public in that format outside the premises of the library or archives." To oversimplify, machine-readable formats must be confined to the building.
They are pirates.
-
@wharrgarbl said in Internet Archive says they'll start ignoring robots.txt:
They are pirates.
It's right there in the name: Internet Arrrrrchive.
-
@wharrgarbl The section you quoted is specific to subsection C, which is strictly limited for copying a deteriorated work or a work whose original distribution format is now obsolete. As HTTP still isn't obsolete, I don't think that would apply, therefore webpages would fall back under subsection A, which doesn't have that limitation.
-
@e4tmyl33t said in Internet Archive says they'll start ignoring robots.txt:
The section you quoted is specific to subsection C, which is strictly limited for copying a deteriorated work or a work whose original distribution format is now obsolete.
And when such copies are made specifically for the purpose of
preservation and security or for deposit for research use in another library or archives
In other words, that section only applies to copies that are made for the library or archive to use internally for "preservation and security" of the material -- i.e., to ensure that their copy doesn't get destroyed, damaged, or lost -- or, it applies to copies which the are destined for deposit into the collections of other libraries and archives.
So, if you're a library or archive, and you want to make offsite backups of your collection, or give copies of items to other libraries or archives for their collections, you should definitely have your lawyers take a good look at subsections (b) and (c). None of it applied to copies which are made for the users themselves, though. Subsection (d) is what actually talks about reproduction and distribution for users:
The rights of reproduction and distribution under this section apply to a copy, made from the collection of a library or archives where the user makes his or her request or from that of another library or archives
As in, when a user makes a request, the library or archive makes one further copy "from the collection" of itself or of another library or archive. That copy becomes the property of the user who requested it (as specified in (d)(1) below) and is legal, so long as:
(d)(1) the copy or phonorecord becomes the property of the user, and the library or archives has had no notice that the copy or phonorecord would be used for any purpose other than private study, scholarship, or research; and
(2) the library or archives displays prominently, at the place where orders are accepted, and includes on its order form, a warning of copyright in accordance with requirements that the Register of Copyrights shall prescribe by regulation.
-
@anotherusername Hmm. I suppose you could consider the client-side cache of the webpage the "user's copy" in that kind of case for that. Interesting.
-
@anotherusername You're not an Oregon registered lawyer, are you? Have a fine.
Wikipedia say they violate european law and give this german paper as a source.
-
Wikipedia says:
Only the content creator can decide where their content is published or duplicated, so the Archive would have to delete pages from its system upon request of the creator.[46]
Which they clearly have a system in place for.
-
@e4tmyl33t look at legal status
In Europe the Wayback Machine could be interpreted as violating copyright laws. Only the content creator can decide where their content is published or duplicated, so the Archive would have to delete pages from its system upon request of the creator.[46] The exclusion policies for the Wayback Machine may be found in the FAQ section of the site.
-
@wharrgarbl said in Internet Archive says they'll start ignoring robots.txt:
@anotherusername You're not an Oregon registered lawyer, are you? Have a fine.
Wikipedia say they violate european law and give this german paper as a source.
Wikipedia says that they could be interpreted as violating European law, and links to a page which, among other things, speculates on whether the Wayback Machine is sufficiently different from ordinary proxy servers (which are perfectly legal) to even be considered as something else in the eyes of the law, and if it is sufficiently different then what other laws might even come into play. It does not say that they violate law; it merely discusses how they might.
edit: okay, the very last paragraph appears to conclude that it would be illegal to operate such a site in Germany. Still, that's not an actual ruling; it's just the opinion of one German lawyer. And besides, sites operated in other countries don't need to follow German law.
edit disclaimer: I read the Google Translate version, not the original German. So, if a native German speaker thinks that it provided a misleading translation, I'd be open to hearing about it.
-
@anotherusername so I could create a site called "the meme archive", fill it with stolen cat macro images from reddit and get rich and be ok with the law?
-
@wharrgarbl I dunno; BuzzFeed might want to sue you for stealing their business model.
-
@wharrgarbl said in Internet Archive says they'll start ignoring robots.txt:
and get rich
What's your profit model?
-
@Yamikuronue 9gag clone?
-
@wharrgarbl said in Internet Archive says they'll start ignoring robots.txt:
9gag
You don't need nine: one will do the job just fine
-
@wharrgarbl 9gag got a ton of investor funding. I doubt you could do that in 2017 for the same idea. And banner ad revenue is dropping every year.
 Internet Archive announces broader crawler scope | bit-tech.net
Internet Archive announces broader crawler scope | bit-tech.net
