Case (in)?sensitive filesystems are :doing_it_wrong:
-
> make thing
Nothing happens ...
> make clean
rm -rf some/path/xyz
> make thing
Nothing happens ...
ls some/path
XYZ

> rm -rf some/path/XYZ
> make thing
Thing gets made.Edit: No, the broken rule in the Makefile is not my doing.
-
@HardwareGeek said in WTF Bites:
> make thing
Nothing happens ...
> make clean
rm -rf some/path/xyz
> make thing
Nothing happens ...
ls some/path
XYZ
> rm -rf some/path/XYZ
> make thing
Thing gets made.Edit: No, the broken rule in the Makefile is not my doing.
Stupid case-sensitive filesystems!

-
Stupid case-sensitive filesystems!
You and I are not alone:
-
@dcon We need to make filesystems case-insensitive, but with Turkish rules so that we don't cause offence by assuming that
iandIare the same letter…
-
@dkf we should make filesystems case insensitive, but with lojban rules so h and ' are the same letter and H is not a letter.
-
Wow, so ignorant of languages other than English.
-
@Greybeard said in WTF Bites:
Wow, so ignorant of languages other than English.
Well, you could retain the cases and still make it case insensitive. So you could have your "Documents" folder, just not a "documents" folder at the same level.
Been bitten by that yesterday because I didn't look too closely and wondered why my website would return 404s for images that were clearly existing and in the right place - well, turns out that "parking_sign.png" and "parking_sign.PNG" are not the same file.
-
@Rhywden And which locale will you use for case folding?
-
@Rhywden And which locale will you use for case folding?
Okay, if you're a special snowflake language then, by all means, make the rest of humanity suffer. I'm not aware of languages based on the Latin character set which would have any problems with this scheme.
-
- well, turns out that "parking_sign.png" and "parking_sign.PNG" are not the same file.
Yeah. and very difficult to tell when Windows hides the file "extensions".
-
Well, you could retain the cases and still make it case insensitive. So you could have your "Documents" folder, just not a "documents" folder at the same level.
Does your filesystem treat I and i as equal? If so then, as @dkf alludes to above, it's
 for Turkic languages.
for Turkic languages.
-
@Rhywden said in [WTF Bites](/post/1015765
Okay, if you're a special snowflake language then, by all means, make the rest of humanity suffer. I'm not aware of languages based on the Latin character set which would have any problems with this scheme.
Why on earth do you consider languages with non-Latin characters to be special snowflake? There are more than a handful of Mandarin speakers, for example.
And we have already established your ignorance of Turkic languages.
-
I'm not aware of languages based on the Latin character set which would have any problems with this scheme.
Your lack of awareness is not my problem.

For various reasons (mostly to do with human languages and their writing systems being TRWTF) the only sane option is to make the filesystem itself be true case preserving; that makes it so that all the OS kernel has to do is shuffle bits about without understanding them. A user interface may do case folding in unambiguous situations, but this is a feature of that UI and not of the OS itself; that's OK, because the UI can at least know what language the user is using, which it is difficult to convey into the OS layer without making everything horrific. (It's still really bad once you consider networked filesystems or removable media; the applicable locale for understanding a filename is not constant.
 I really really mean this.)
I really really mean this.)The advantage of putting the onus on the UI is that the cost of understanding the locale is being payed much more closely to the point where it matters. There's a lot of software which really shouldn't have to care about this stuff at all; forcing that to handle the complexity is just bass-ackwards.
-
I'm not aware of languages based on the Latin character set which would have any problems with this scheme.
So never heard of German? What's lowercase AE? ä or ae? Could be either. Same goes for SS -> ss or ß.
-
@ixvedeusi said in WTF Bites:
I'm not aware of languages based on the Latin character set which would have any problems with this scheme.
So never heard of German? What's lowercase AE? ä or ae? Could be either. Same goes for SS -> ss or ß.
You may not be aware, but I am German. And here's the thing: Are you unable to understand the word "Teetasse" just because I spelt it "teetasse"?
No?
Then the case of the word has no immediate impact on its meaning - it's rather an artifact of language and conveys next to no useful additional information. I mean, just look at the English language - they have even fewer cases where a word is spelt with an upper case and yet there's no real problem understanding it.
-
-
@dkf
What have I done? I'm a coffee drinker myself
-
-
@ixvedeusi said in WTF Bites:
What's lowercase AE? ä or ae? Could be either. Same goes for SS -> ss or ß.
This is not really a big problem. A "case-insensitive" filesystem that does not treat
äas equivalent toaeandßas equivalent tosswon't really offend most Germans. However a filesystem that treatsIandias equivalent will offend Turks, because for them,iis only equivalent toİandIis equivalent toı.You may not be aware, but I am German. And here's the thing: Are you unable to understand the word "Teetasse" just because I spelt it "teetasse"?
But do you expect a "case-insensitive" filesystem to treat
SSas equal toßor not? Because according to German rules it is, but according to rules of other languages it might not be. Ok,ßis rather bad example, because it is mostly German-specific; there are other extensions of Latin alphabet that are not, most important being the dotless i.
-
@ixvedeusi said in WTF Bites:
What's lowercase AE? ä or ae? Could be either. Same goes for SS -> ss or ß.
This is not really a big problem. A "case-insensitive" filesystem that does not treat
äas equivalent toaeandßas equivalent tosswon't really offend most Germans. However a filesystem that treatsIandias equivalent will offend Turks, because for them,iis only equivalent toİandIis equivalent toı.You may not be aware, but I am German. And here's the thing: Are you unable to understand the word "Teetasse" just because I spelt it "teetasse"?
But do you expect a "case-insensitive" filesystem to treat
SSas equal toßor not? Because according to German rules it is, but according to rules of other languages it might not be. Ok,ßis rather bad example, because it is mostly German-specific; there are other extensions of Latin alphabet that are not, most important being the dotless i.There's no uppercase ß so the question does not even pose itself.
-
@Greybeard said in WTF Bites:
Why on earth do you consider languages with non-Latin characters to be special snowflake? There are more than a handful of Mandarin speakers, for example.
What good is cultural imperialism if we can't impose ASCII on the world?
-
There's no uppercase ß so the question does not even pose itself.
Serious question: What result do you expect from
to_upper("ß"). You might not want to write that in normal written German but we're talking about stuff that happens within a computer. That's not at all bound by grammar or spelling and I'm sure there are multiple ways you could get to some operation like that.
-
@boomzilla said in WTF Bites:
Serious question: What result do you expect from
to_upper("ß").Wikipedia suggests
ẞ.U+1E9E LATIN CAPITAL LETTER SHARP S
-
teetasse
Yes, I'd understand "teetasse", but I'd expect a case-insensitive file system to find the folder "WASSERFAELLE" if I do a search for "wasserfälle". Also, would your hypothetical case-insensitive file system allow a file "WASSERFAELLE.PNG" next to "wasserfälle.png"?
What I'm trying to say is, much like date and time, case conversion seems obvious and trivial to humans, because it is in many cases and can be done mostly right by intuition in many others, but for a computer program to work in a reliable matter you have to be able to handle all cases correctly, or your super-intuitive "do-what-I-mean" system will come back to bite you when you least expect it.
-
@boomzilla said in WTF Bites:
to_upper("ß")
In German, to_upper("ß") is "SS", there's no uppercase single-letter equivalent.
EDIT: But there's also the lower-case "ss", so to_upper() is a lossy conversion.
-
@ixvedeusi said in WTF Bites:
teetasse
Yes, I'd understand "teetasse", but I'd expect a case-insensitive file system to find the folder "WASSERFAELLE" if I do a search for "wasserfälle". Also, would your hypothetical case-insensitive file system allow a file "WASSERFAELLE.PNG" next to "wasserfälle.png"?
What I'm trying to say is, much like date and time, case conversion seems obvious and trivial to humans, because it is in many cases and can be done mostly right by intuition in many others, but for a computer program to work in a reliable matter you have to be able to handle all cases correctly, or your super-intuitive "do-what-I-mean" system will come back to bite you when you least expect it.
You're conjuring up some very dodgy cases with suspect logic. The lowercase equivalent to "WASSERFAELLE" is "wasserfaelle". There is "Ä" as well as "ä".
Are you sure you're not confusing issues with the standard ASCII table versus LATIN-1 now?
-
@ixvedeusi said in WTF Bites:
I'd expect a case-insensitive file system to find the folder "WASSERFAELLE" if I do a search for "wasserfälle".
But “älg.png” doesn't map to “AELG.PNG” in Swedish, which has
äas a totally separate letter toa(it comes afterzin the dictionary). So even that one symbol runs you into trouble unless you know the locale and teaching the OS core about the locale is major WTF territory given just how stupidly complicated human languages and writing systems really are.People used to working in one locale only think it is easy. Pah!
-
You're conjuring up some very dodgy cases with suspect logic.
This is completely intentional and part of my point. If you bake features like these into the OS, you must get all cases right or you're guaranteed make some people extremely unhappy. The potential pitfalls of institutionalized case insensitivity are by far not worth the anecdotal little inconveniences (IMHO mostly due to PEBCAK) which case sensitivity may cause.
And no, these issues are in no way tied to any character encoding (or even computers), they are inherent to human language and the differences between languages.
-
@ixvedeusi So, you're intentionally spouting bullshit in order to create a point for you which is patently false. Got it.
-
If that's how you see it I very much hope I'll never be forced to use any library or program in whose creation you have been involved. As long as that's the case, whatever, suit yourself.
-
@ixvedeusi Make a real and valid argument and I'm listening.
-
you're intentionally spouting bullshit
No, you're just assuming that something that really really isn't simple is trivially soluble. It's only easy to deal with these things in the case where everything that that computer does is in one language in one country. (Probably. There might be cases where there are significant locale changes within a country without changing the language, but I can't think of any off the top of my head.)
-
@dkf Naw, his "wasserfälle" argument is bullshit. Try it: Go into the editor of your choice, try to find a string and turn off case sensitivity.
He stated that he would expect to find "WASSERFAELLE" as well.
Strangely enough, he won't.
-
@ixvedeusi said in WTF Bites:
I'd expect a case-insensitive file system to find the folder "WASSERFAELLE" if I do a search for "wasserfälle".
Your expectation is kind of wrong here though. It should find "WASSERFÄLLE" if you search for "wasserfälle" and "WASSERFAELLE" if you search for "wasserfaelle". There is a perfectly valid uppercase ä: Ä
edit: got ninja'd a bit there. Stupid internet connection just breaking ^^
-
Your expectation is kind of wrong here though. It
shouldwould find "WASSERFÄLLE" if you search for "wasserfälle" and "WASSERFAELLE" if you search for "wasserfaelle". There is a perfectly valid uppercase ä: ÄIf the result does not match the expectation, it's necessarily the expectation which is wrong because I
, yes?And yes, Ä is a perfectly valid uppercase ä, but so is AE. If your algorithm doesn't get that, it's wrong.
-
@ixvedeusi said in WTF Bites:
And yes, Ä is a perfectly valid uppercase ä, but so is AE. If your algorithm doesn't get that, it's wrong.
No it isn't. Stop bullshitting.
-
@ixvedeusi said in WTF Bites:
And yes, Ä is a perfectly valid uppercase ä, but so is AE in German. If your algorithm doesn't get that, it's wrong.
FTFY. And that's the part that's awful. The OS has to figure out exactly what language and writing system a string is in. While being aware that strings can be in several different languages at once. (Yes, that's very very possible.) It's a screaming pit o' WTF out there and just dealing with the bytes without trying to get smarter is an entirely reasonable approach.
The user interface may do more; that's user-level code.
-
@dkf Guys, seriously? You're mixing up LATIN-1 to ASCII conversion and case sensitivity here.
-
-
FTFY
Thanks, yes, the "in German" is implied in all my responses and I should have been more specific about it, because the point of my argument is exactly that this kind of thing is entirely dependent on locale and you cannot have a single algorithm which does the right thing for everyone.
@dkf Guys, seriously? You're mixing up LATIN-1 to ASCII conversion and case sensitivity here.
Why on earth do you keep thinking this has anything at all to do with character encoding? It's all about the letters, not the bits which happen to be used to represent them.
-
@ixvedeusi said in WTF Bites:
so is AE
You may think so, but I never see anybody using that anymore. That was common back when umlauts weren't available in most electronics, but that hasn't been an issue since I don't know how long...
-
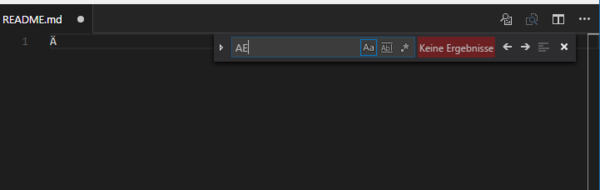
@ixvedeusi Up there is an example of an algorithm which somehow doesn't equate "AE" with "Ä". I can pull up any number of code / text editors which will yield similar results.
Do you really want to go down this path of "Your algorithm must be wrong, then"?
-
@ixvedeusi said in WTF Bites:
it's necessarily the expectation which is wrong
In this case? Yes. I don't think any software developer I know would agree that "AE" equals "Ä" (or "ä" either)
-
@ixvedeusi said in WTF Bites:
it's necessarily the expectation which is wrong
In this case? Yes. I don't think any software developer I know would agree that "AE" equals "Ä" (or "ä" either)
As it is a lossy conversion, the equality sign would be quite wrong.
-
@Rhywden That's another point. There's a lot of words containing "ae" which is not "ä" but rather two separate characters. How would a computer decide which is which? "ae" is just an ancient way to write "ä" in systems that do not know about umlauts. It is (or should be) entirely unnecessary nowadays
-
There's a lot of words containing "ae" which is not "ä" but rather two separate characters.
My point exactly.
-
@ixvedeusi said in WTF Bites:
There's a lot of words containing "ae" which is not "ä" but rather two separate characters.
My point exactly.
Nope. You were saying the exact opposite, namely that you were expecting them to be treated as the same character.
-
I can pull up any number of code / text editors which will yield similar results.
"My programs don't do what you say they should, so your language must be wrong."
-
@Yamikuronue said in WTF Bites:
I can pull up any number of code / text editors which will yield similar results.
"My programs don't do what you say they should, so your language must be wrong."
Well, then show me the editor which does what he says. Don't expect me to hold my breath.
-
It is (or should be) entirely unnecessary nowadays
It definitely was necessary at some time, and I'm still quite used to "ae may be ä" (though thinking about it, I have to admit I haven't been confronted with it for some time, but that may be because I'm not using my written German very often recently). Anyway, this is an example of why case insensitivity is far from trivial and entirely locale-dependent.
 Case-sensitivity is the past trolling us / Tiamat
Case-sensitivity is the past trolling us / Tiamat